
Swipe to navigate
In the weeks following OpenAI’s release of ChatGPT, artificial intelligence (AI) captured our collective attention to an unprecedented extent. It has been more than a year since the company introduced its chatbot to the public and the hype is still going strong.
As a result, every leader—from startup founders to Fortune 100 CEOs—has been asked to explain what she or he is “doing with AI.” In response to this request, many leaders are exploring the possibility of creating AI-native products for their customers.
To help the startup ecosystem and large enterprises alike, we are open-sourcing our proprietary framework for mapping the different facets of AI and machine learning (ML). It is a highly visual and useful tool called the Glasswing AI Palette.
First, some background: The Glasswing Ventures team has proudly led the charge in the frontier technology and AI investment landscape since 2010, propelling groundbreaking companies across various industries. Our thesis-driven approach and focus on early-stage companies developing AI-native products—specifically in the enterprise and cybersecurity markets—stems from our deep expertise and understanding of the transformative power of AI.
Designed to help business leaders understand AI through the lens of use cases and to help investors assess the defensibility of the AI-native products they are evaluating, the Glasswing AI Palette illustrates how common architectures, techniques, training methodologies, data, and use cases work together. It is a one-of-a-kind, living resource that we plan to periodically update as the technology progresses and as the community shares feedback—which we encourage and welcome.
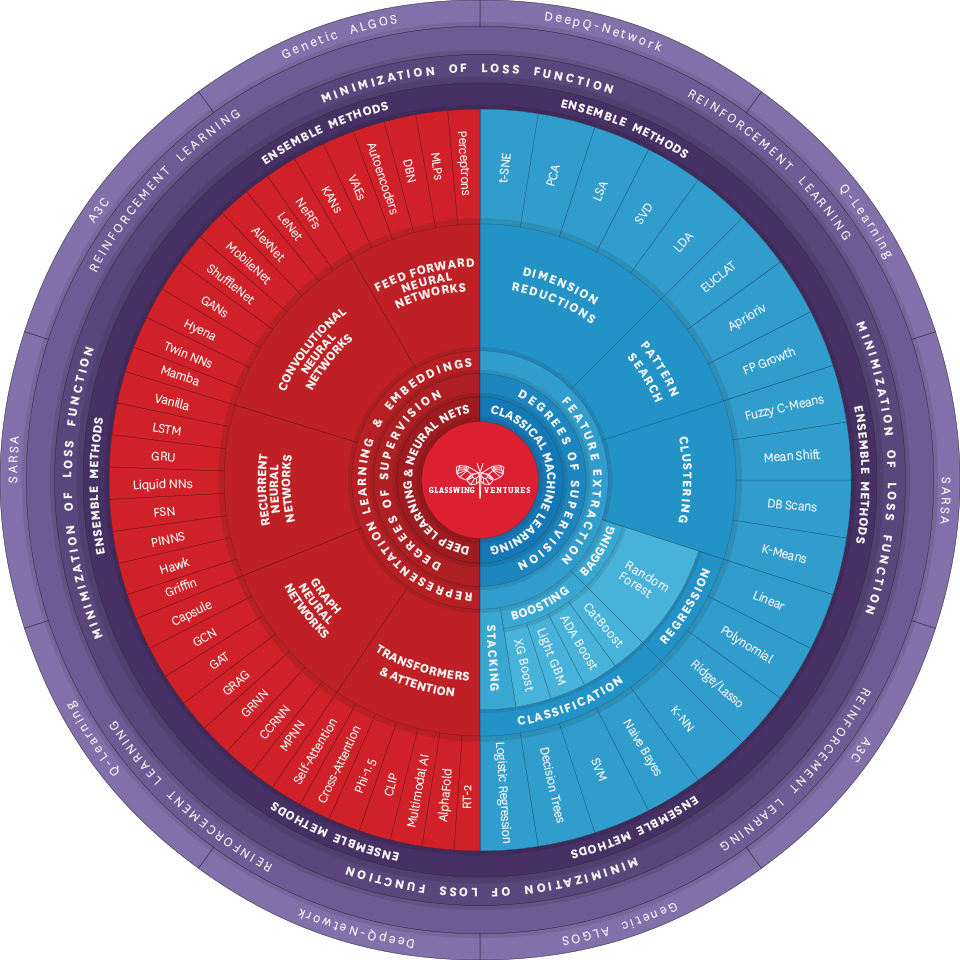
AI, in its entirety, encompasses a vast array of learning methods and models, including ML and Deep Learning, which are two key areas covered by the Glasswing AI Palette, but also extends to search and optimization, decision-making mechanisms, such as Markov Decision Processes, knowledge representation and reasoning, and even game theory. The Glasswing AI Palette, however, focuses on a very important subset of this broad spectrum: ML and Deep Learning. This is particularly relevant as Deep Learning has shown rapid advancements and increasing ability to encroach upon other AI domains.
If we consider AI—the ability of a system to mimic humans to complete tasks—as the what, then ML is the how. The Glasswing AI Palette explicitly focuses on ML as a proxy for delivering AI-native algorithms and software. Accordingly, it is divided into two halves, one for each of the major forms of ML: Classical ML and Deep Learning.
Whereas Classical ML models are better suited to analyze simple datasets and require significant human interaction to produce results, Deep Learning models leverage multi-layered neural networks to autonomously identify patterns and features within data, which makes them significantly more adept at handling large, intricate data sets with minimal human input and allow for much more model flexibility.
In this walkthrough, we will take a closer look at both Classical ML and Deep Learning, as well as the Ensemble Methods that combine their capabilities. Then, we will describe the various Degrees of Supervision employed for training based on use cases and available data sets. Finally, we will describe the distinct types of data required to train Classical ML and Deep Learning models and highlight common use cases for each.
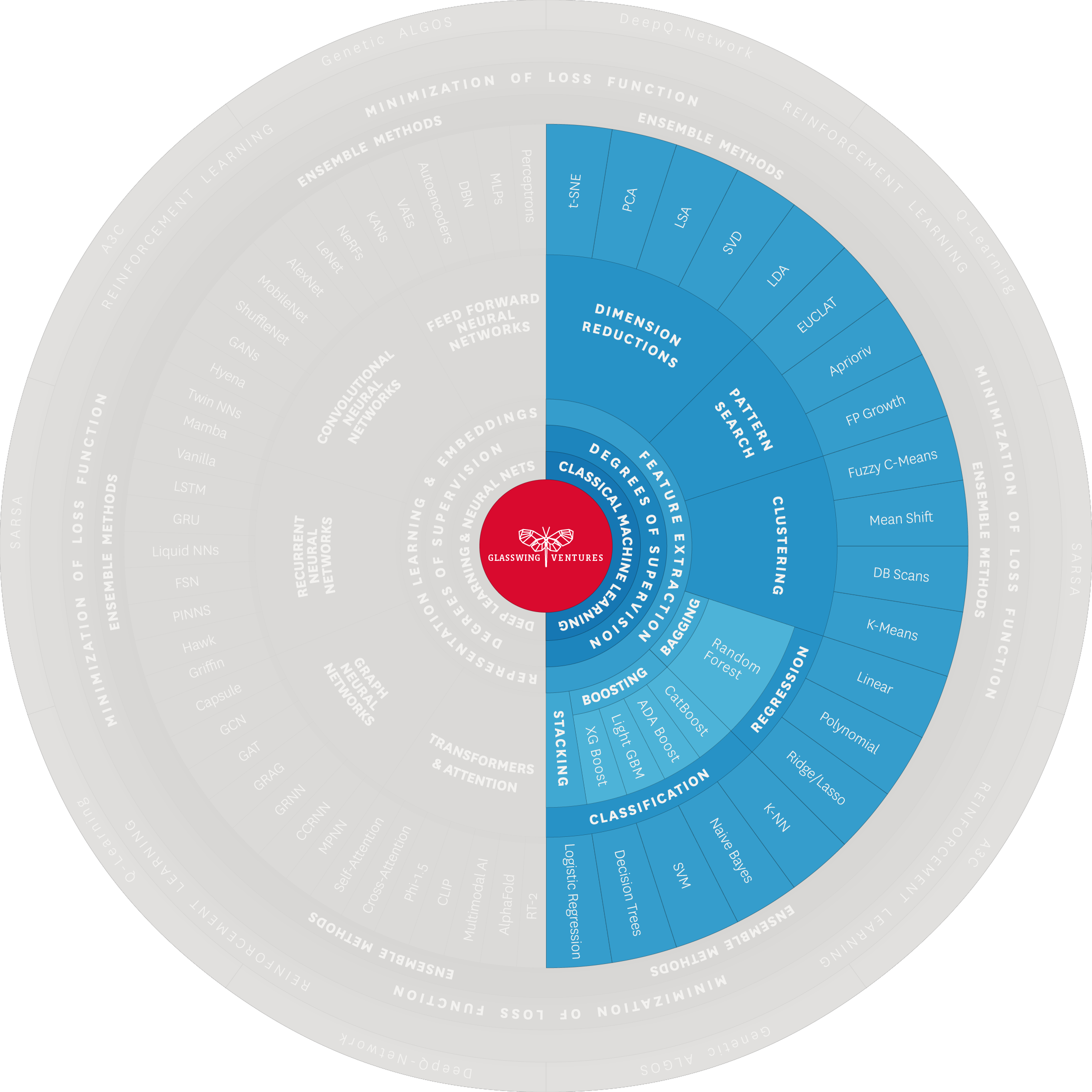
Underneath the Classical ML umbrella are well-known techniques that have existed for decades, including regression, classification, and clustering.
Regression entails training the model to predict a continuous value based on inputs—e.g., estimating real estate property prices based on location, size, etc.
Classification involves training the model to assign inputs to distinct categories—e.g., separating spam emails from non-spam emails.
Clustering consists of training the model to identify patterns in the data set and group inputs together accordingly—e.g., segmenting customers based on purchasing behavior.
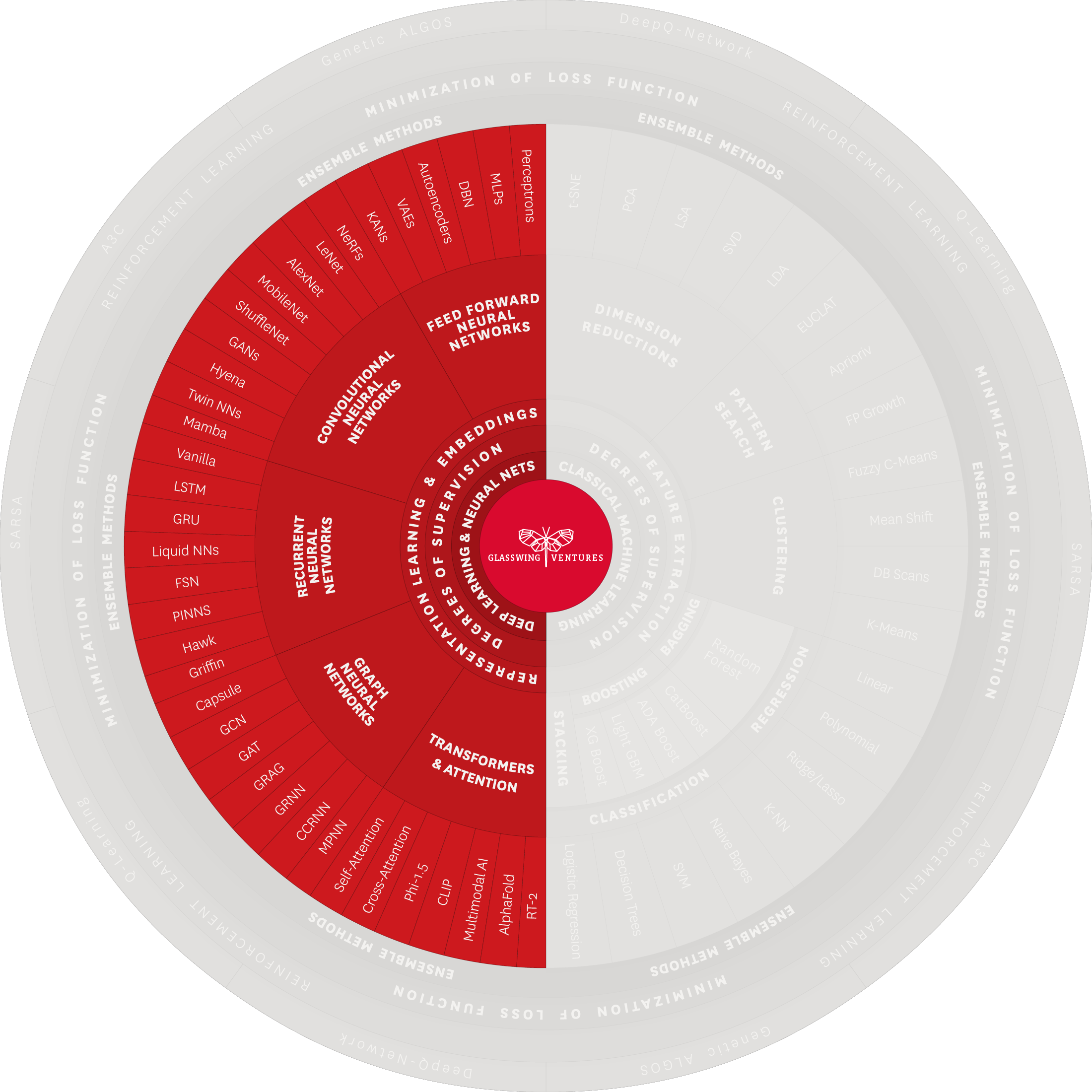
Deep Learning is characterized by its use of multi-layered neural networks. These networks stand out for their capability to autonomously learn the optimal representation of data, whether through supervised or unsupervised learning, thus, eliminating the need to manually define features, a key shift from the manual feature extraction characteristic of Classical ML. Because Deep Learning leverages hierarchical learning—where initial layers identify basic elements like edges in images or sound frequencies, and subsequent layers enhance and refine these representations to build progressively more complex ones–it can effectively process data like images, audio, and text.
The breadth of Deep Learning is further exemplified by the variety of neural network architectures that can be constructed, each suited to different types of tasks and use cases. In the Glasswing AI Palette, we have narrowed the multitude of architectures into five key classes. As we delve into each of these five architecture classes, we uncover the myriad ways in which Deep Learning continues to push the boundaries of AI to provide a variety of widespread practical applications in the real world. At the same time, leveraging Deep Learning also comes with challenges, including the need for extensive data sets and significant computational resources, as well as difficulties with interpretation and opaqueness.
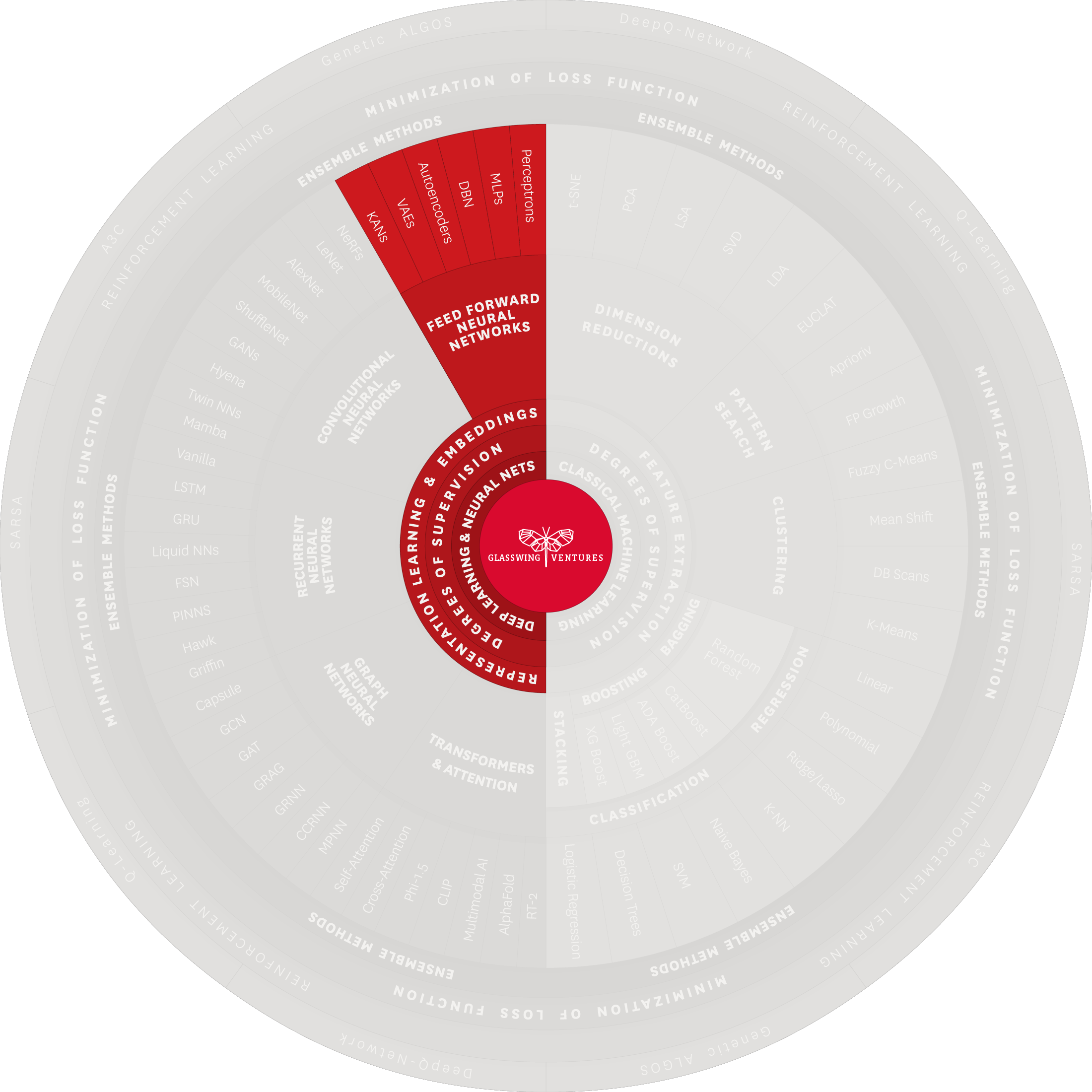
Since their ideation, Feedforward Neural Networks (FNNs) have been a bedrock of neural network technology. Characterized by straightforward data processing—where information travels in one direction from input to output—FNNs represent the first class of deep learning architectures, and for this reason they are commonly called “vanilla” neural networks.
Key structures include the perceptron, which started as a relatively simple model in FNNs and has evolved into more sophisticated systems integral to modern technology. Its basic structure consists of input nodes connected to an output node and it is designed to classify inputs by weighting and summing them before triggering an output. This algorithm has laid the groundwork for more complex systems to develop.
Applications: FNNs have been pivotal in advancing technologies such as facial recognition, image processing, and data compression. Additionally, multi-layer perceptrons have advanced to support the more sophisticated Neural Radiance Fields (NeRFs), which can convert 2D photographs into 3D models, revolutionizing fields like virtual reality, game design, manufacturing, and robotics. In the sphere of data compression, FNNs play a crucial role, efficiently reducing file sizes while maintaining essential information. This functionality is particularly vital in streaming services, where it enhances data transmission efficiency, ensuring a seamless experience.
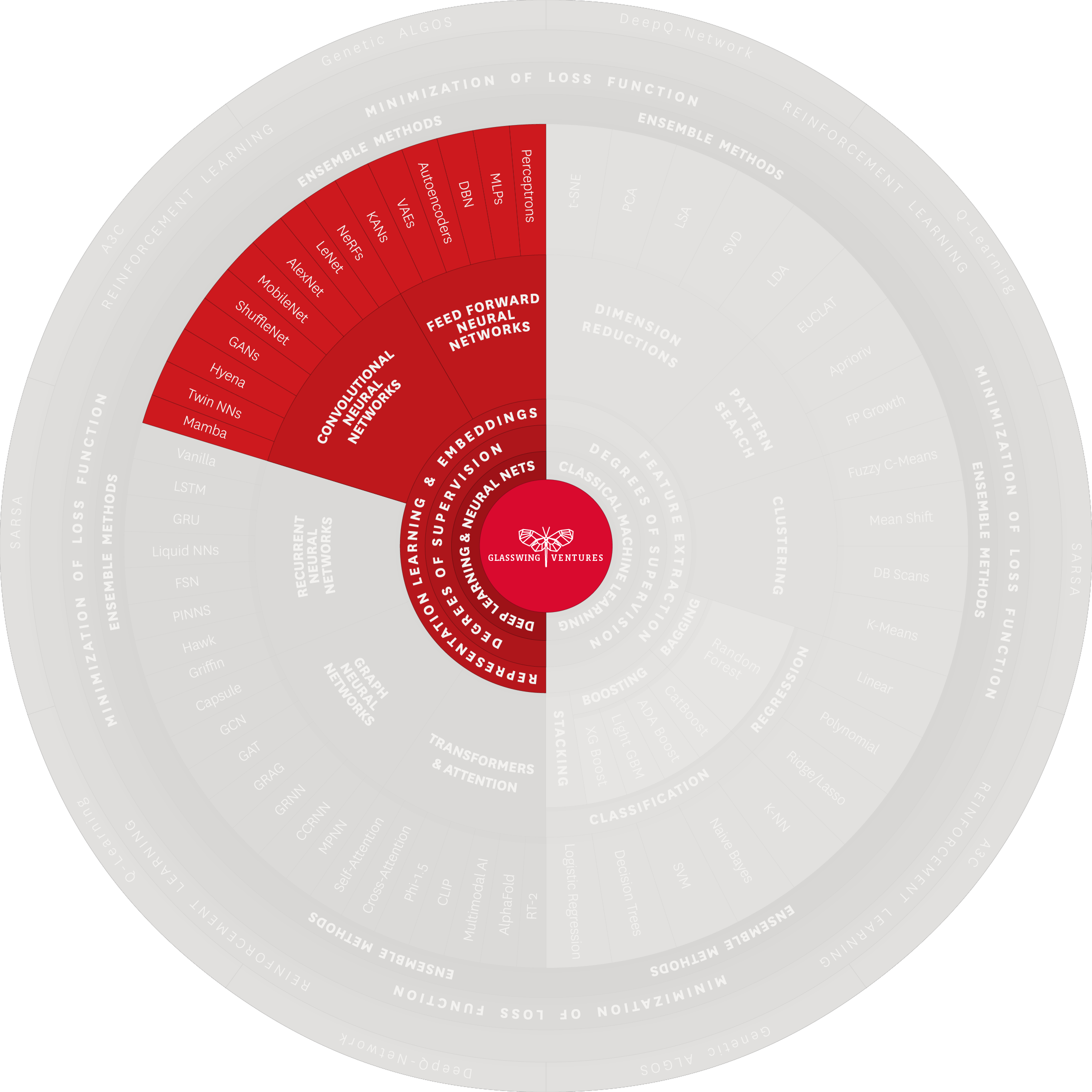
Convolutional Neural Networks (CNNs) build on the foundation of FNNs, specializing in tasks such as pattern recognition and visual data processing. They use multiple layers with specialized convolutional filters to extract distinctive features from input data. This multilayered approach enables CNNs to excel in image classification, object detection, and other intricate visual tasks.
Key structures include LeNet, a 1998 milestone in image recognition by Yann LeCun and collaborators including Léon Bottou and Yoshua Bengio, which was adopted by the US Postal Service to read handwriting. AlexNet expanded on LeNet, revolutionizing computer vision with deeper layers. This innovation also laid the groundwork for Generative Adversarial Networks (GANs), which involve two competing models, often one being a CNN. GANs are critical to the creation of synthetic data, which is computer-generated data created to augment or replace real data in order to improve AI models and protect sensitive information.
Applications: CNNs are crucial in image and video recognition for surveillance and security systems, enabling accurate object and facial recognition. In the manufacturing sector, they enhance quality control and defect detection on assembly lines. Glasswing portfolio company Retrocausal, for example, utilizes computer vision to augment manufacturing assembly line workers. This broad range of applications underscores the versatility of CNNs in interpreting and utilizing visual information.
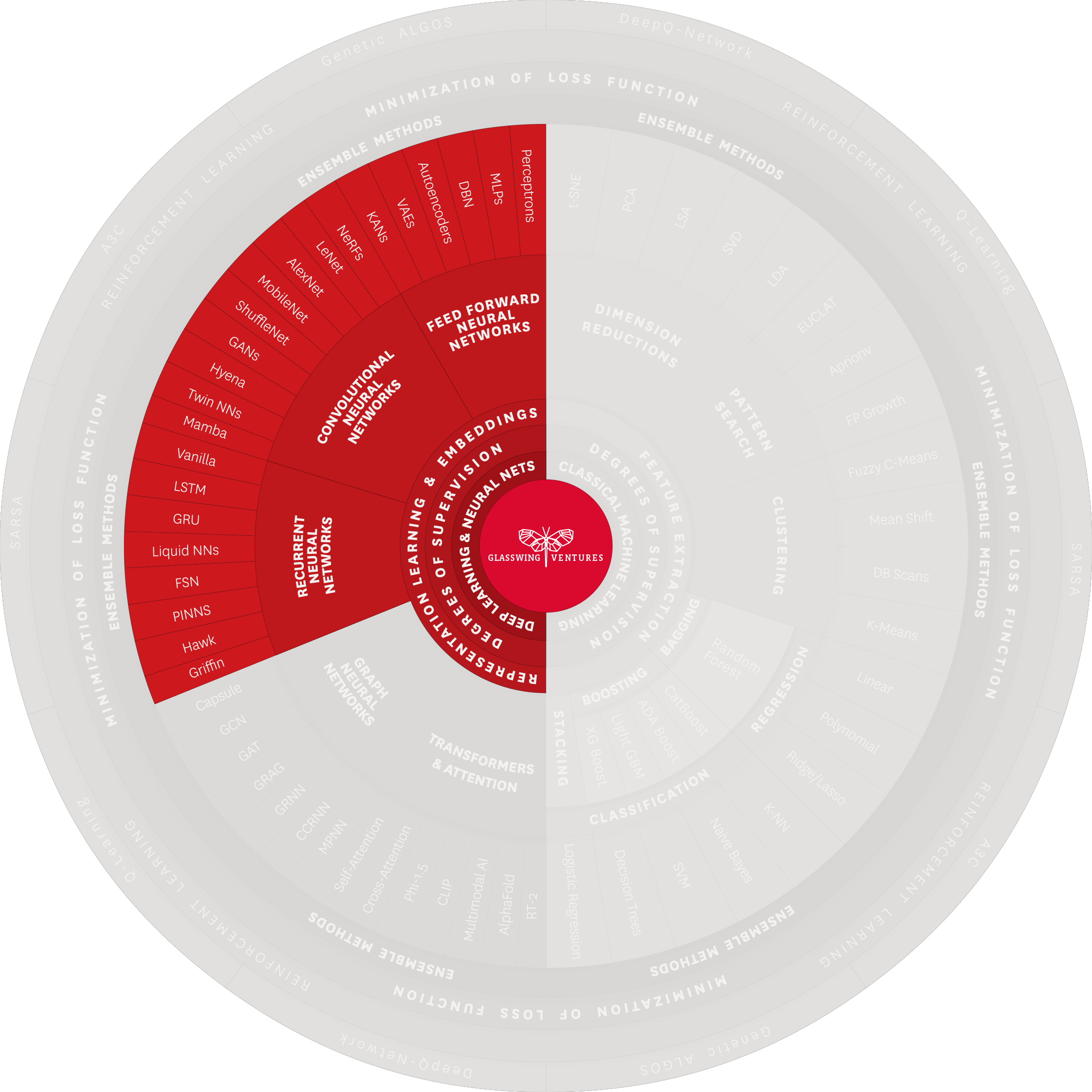
The sibling of Feedforward Neural Networks, Recurrent Neural Networks (RNNs) process information bi-directionally. Compared to FNNs, which ignore any relation between past and future data, RNNs leverage specialized neurons capable of relaying information in both directions. RNNs deal with sequential data or tasks that require memory, such as speech recognition and time-series analysis, where each point depends on the previous and influences the next.
Key structures include Physics-Informed Neural Networks (PINNs), which leverage real-world physical equations as bounds on RNN computations. Glasswing portfolio company Basetwo has developed a platform leveraging PINNs to improve complex manufacturing processes. RNNs also include Liquid Neural Networks, which dynamically adjust their own model size by distilling tasks and dropping irrelevant information.A final technique worth highlighting are Long Short-Term Memory Networks (LSTM), which introduces memory to RNNs and addresses a training limitation called the vanishing gradient. This advancement is foundational for language use cases and lays the groundwork for voice recognition systems such as Apple’s Siri and Amazon Alexa.
Applications: RNNs have found their niche primarily in tasks involving sequential data, such as language processing. Apart from language modeling, where they predict the next word or character in text sequences, RNNs are key in machine translation, translating text while preserving context and meaning. In speech recognition, they convert spoken language into text, thus enabling voice-controlled applications. Their unique ability to handle sequential data and retain previous information makes them ideal for contexts in which the sequence and continuity of data are essential.
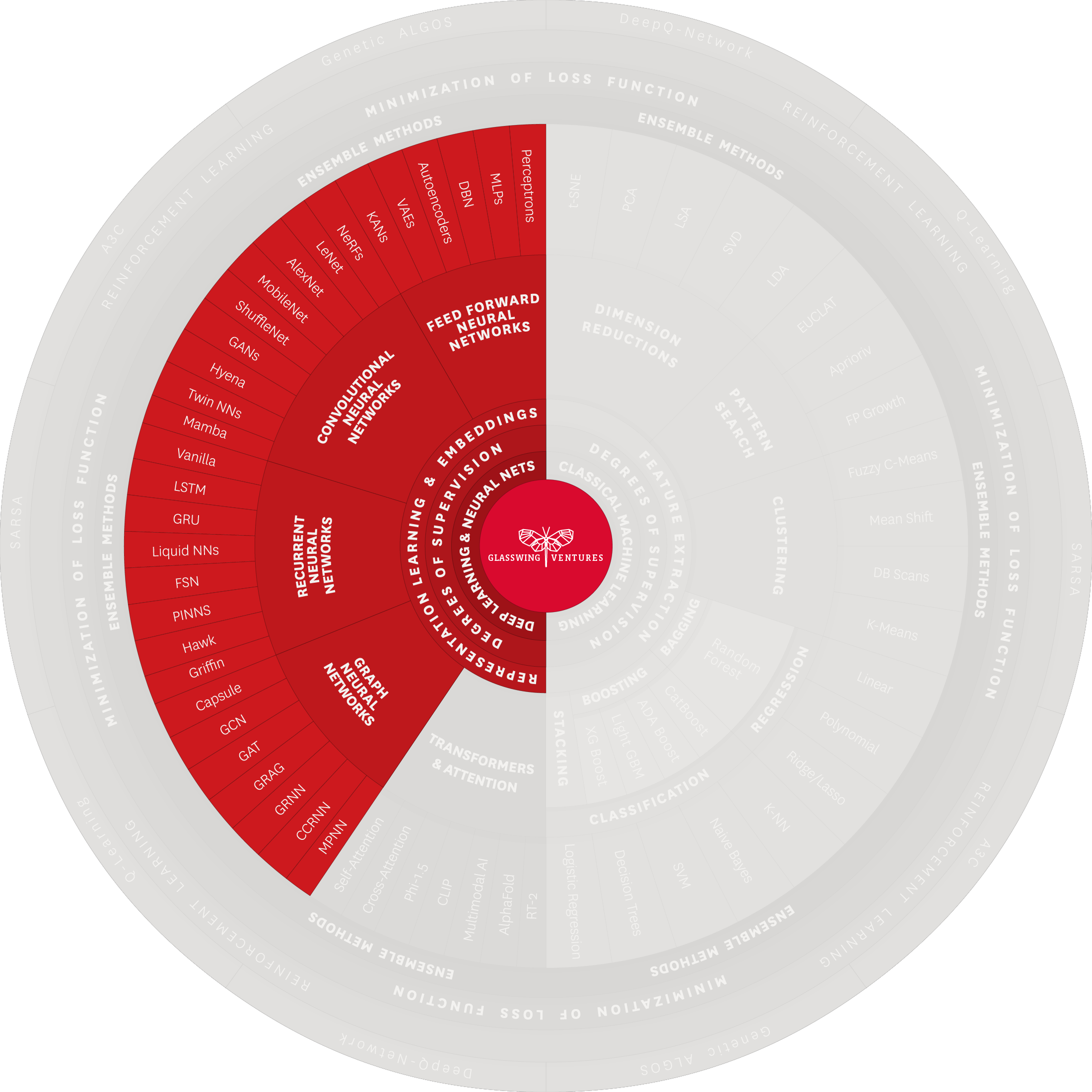
Graph Neural Networks (GNNs) are a type of neural network designed to process data represented in graph structures, where the dataset consists of nodes (objects) and their interconnections. GNNs are particularly powerful because they can understand and analyze how data points are connected to each other, which is crucial in situations where these relationships are just as important as the data points themselves.
Key structures include Graph Convolutional Networks (GCNs), one of the most common types of GNN due to their scalability and computational efficiency. These networks are equipped with a convolutional layer, an innovation that enables the model to leverage both the features of a node and its surroundings in order to make predictions. Graph Attention Networks (GAT), another type of GNN, are unique in that they leverage self-attention mechanisms to calculate coefficients measuring the importance of neighboring nodes.
Applications: GNNs have an array of applications due to the popularity of knowledge graphs, graph databases, and other types of structured graph data sets. LinkedIn is a prime example where GNNs are used to analyze the intricate connections between individuals. In addition, in cybersecurity, they are used to safeguard networks by detecting subtle, stealth, and complex intrusion patterns. These are only a few practical applications that highlight how GNNs are powerful in data analysis and decision-making.
Transformers are the newest class of Deep Learning architecture, first developed in the seminal 2017 paper “Attention is All You Need” by researchers at Google and the University of Toronto. Exemplified by OpenAI’s GPT, a transformer is a neural network that uses a self-attention mechanism to learn the relationships between the components of an input sequence, e.g., words in a paragraph, and calculates a contextually relevant output. In fact, all of Generative AI, from large language models (LLMs) such as GPT-4 to diffusion models such as DALL-E and Midjourney, is found in this one slice of the Palette. Given how revolutionary Generative AI has been within society over the last year, it becomes easier to see the magnitude of AI’s wider value across all techniques and architectures.
Key structures include Google’s Bidirectional Encoder Representations from Transformers (BERT), one of the first language models to process words through pre-training, by way of Unsupervised Learning (more on this below). Generative Pre-trained Transformers (GPT), built by OpenAI, is another notable class of models known for powering ChatGPT with autoregressive language modeling and language generation.
Applications: Transformers have been revolutionary in powering the development of large language models (LLMs), being particularly well-suited for large-scale text generation, summarization, Q&A, and sentiment analysis. Transformers have also been adapted for image generation. Glasswing portfolio company Common Sense Machines utilizes transformer technology alongside neural radiance fields (NeRFs) to quickly create realistic digital assets and augment AI training datasets with realistic simulated data.
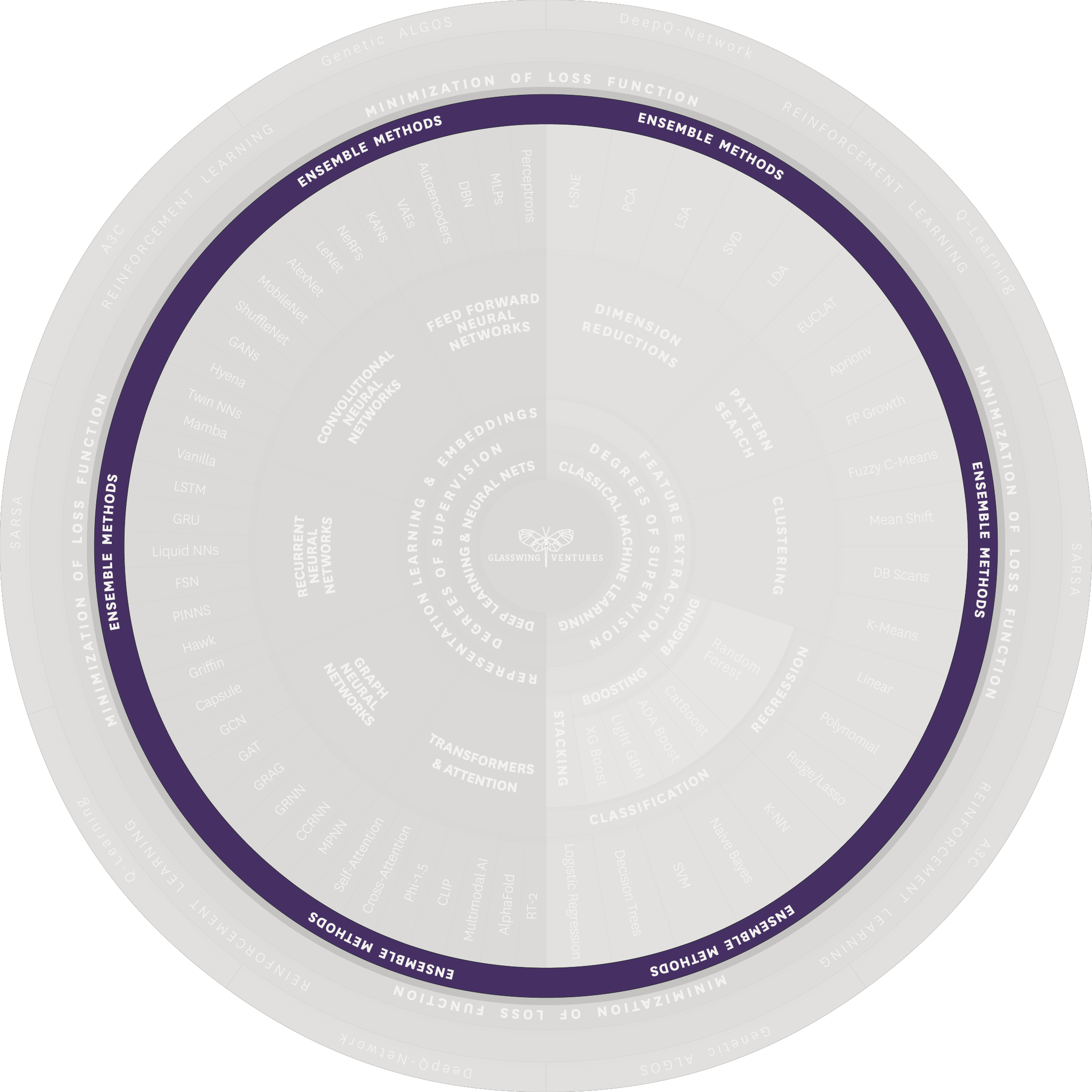
Pivotal to both Classical ML and Deep Learning are Ensemble Methods, which combine multiple techniques and models to improve prediction accuracy and robustness. These methods work akin to consulting a panel of experts, whereby each model contributes its knowledge to reach a more accurate conclusion. Ensemble Methods can be used to combine architectures and techniques within Classical ML, within Deep Learning, or across both. The resulting combinations give rise to a large multitude of possibilities for architectures and techniques, creating the powerful opportunity for data scientists and engineers to select the best ensemble models for the problems they are solving.
The main ensemble methods are Stacking, Bagging, and Boosting, with the latter being applicable particularly to Classical ML.
Stacking consists of training various models, like a team of experts each solving a different part of a problem, and then uses a ‘meta model’ akin to a team coordinator to synthesize their predictions into a single, more accurate outcome. It is like combining the best pieces of advice from a diverse team to reach the best decision.
Bagging is like conducting multiple surveys on the same question and then combining the results for a more reliable answer. It involves training the same model multiple times on different data subsets and then aggregating their predictions, typically through averaging or voting, to produce a more accurate overall prediction.
Boosting, primarily associated with Classical ML, resembles a relay race where each participant works to improve upon the previous one’s performance. It sequentially builds multiple simple models, each aiming to correct the mistakes of its predecessors, culminating in a sophisticated and robust final model.
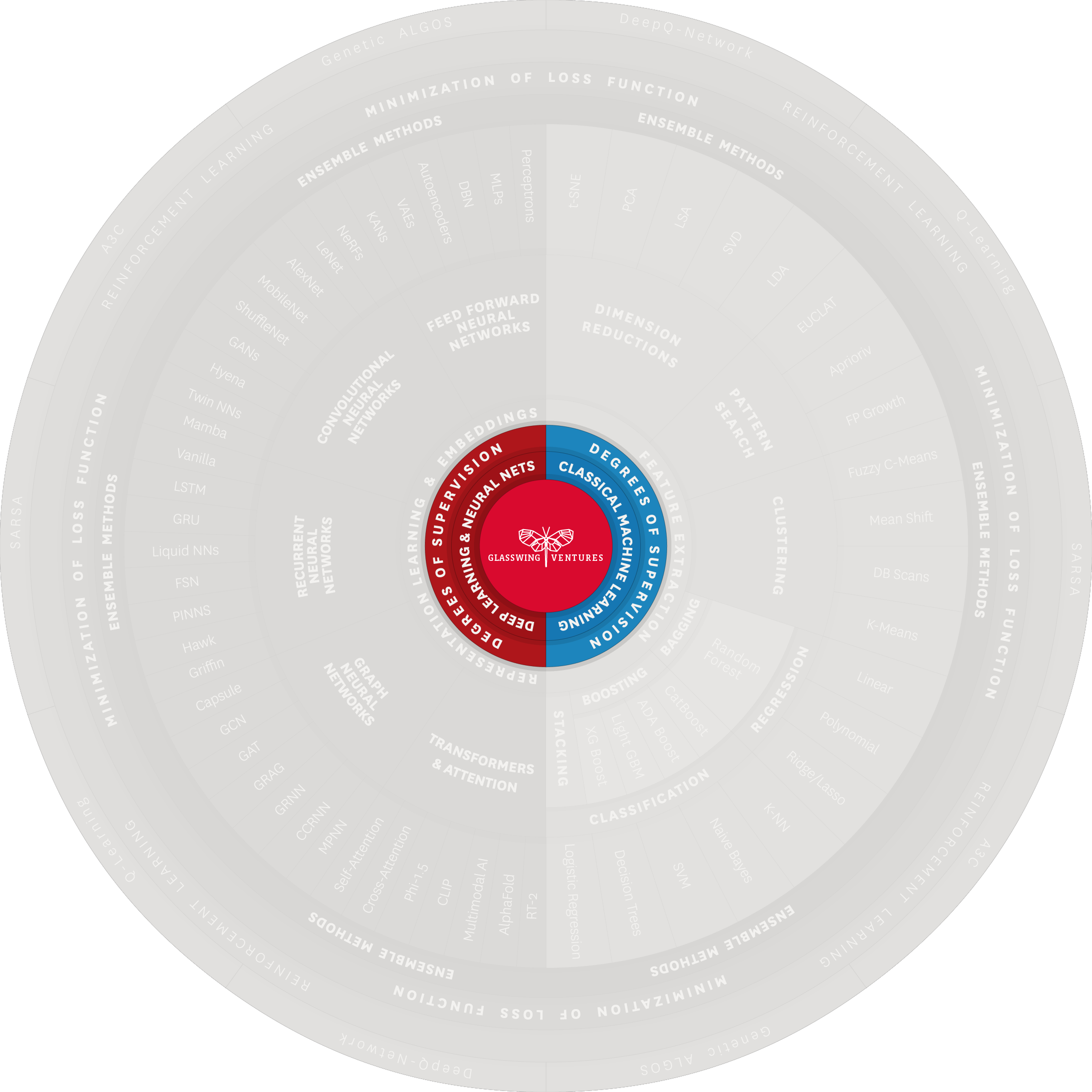
Also pivotal to both Classical ML and Deep Learning is the concept of Degrees of Supervision, which fundamentally influences one’s choice of algorithm and approach for a given application. Understanding this concept requires an appreciation for how much human input and guidance is required in the model training process. There are primarily three degrees of supervision: Supervised Learning, Unsupervised Learning, and Semi-Supervised Learning.
Supervised Learning involves training models on a labeled dataset, where every piece of input data is directly linked with a specific output label. This association is critical, as it provides the model with clear examples of what it needs to learn. Data scientists are integral in this process of human in the loop. They meticulously prepare the dataset, a task that requires careful identification—spotting and selecting—and annotating—labeling or marking—each piece of input with the correct output. This preparation enables the model to understand and learn the relationship between the available input and the desired output.
Supervised Learning is often applied to techniques such as regression (where the model is trained to predict a continuous value based on input data) and classification (where the model categorizes inputs into distinct classes or labels). In deep learning, supervised learning is often employed in image/face recognition—e.g., every time a photo is tagged on Facebook.
The application of Supervised Learning is seen in predictive analytics, where models forecast future trends based on historical data, and in image recognition systems, where models identify and label objects in images. The strength of Supervised Learning lies in its ability to provide precise, reliable results when trained on well-labeled data.
Unsupervised Learning entails training models on an unlabeled dataset, where the input data does not come with predefined labels or outputs. In this scenario, the model independently explores and analyzes the data to find patterns or structures. The absence of explicit guidance means that the model must discern any inherent groupings or relationships in the data on its own. This self-guided exploration is a key characteristic of Unsupervised Learning.
Unsupervised Learning is often applied to techniques such as clustering (where the model groups similar data points together based on inherent similarities) and dimensionality reduction (where the model simplifies complex datasets by distilling them down to the most significant features). In deep learning, unsupervised learning is leveraged to create embeddings, which are further utilized by transformers to identify relationships between words and phrases.
The application of Unsupervised Learning is used for anomaly detection, customer segmentation, recommendation engines, and self-driving cars. The strength of Unsupervised Learning lies in its ability to discover hidden structures in data, offering insights that might not be apparent with supervised methods.
Semi-Supervised Learning combines elements of both Supervised and Unsupervised Learning, with the model being trained on both labeled and unlabeled data. Labeled data provides clear guidance for the model, enabling it to learn from explicit examples. The model then takes this guidance from labeled data and explores and discovers patterns independently in the unlabeled data, akin to Unsupervised Learning.
Semi-Supervised Learning encompasses self-training, where the model trains on labeled data and applies its predictions on unlabeled data (think of a student who learns from a textbook and applies her knowledge to real world scenarios), and co-training, where two or more models are trained on different views of the data and then make predictions on the unlabeled data. In this case, the models learn from each other’s predictions. A helpful analogy might be two football players who have trained on different teams but come together on one team to deliver a win.
The application of Semi-Supervised Learning is widely seen in scenarios where labeled data is scarce or expensive to obtain, such as natural language processing, image recognition, and web content classification.
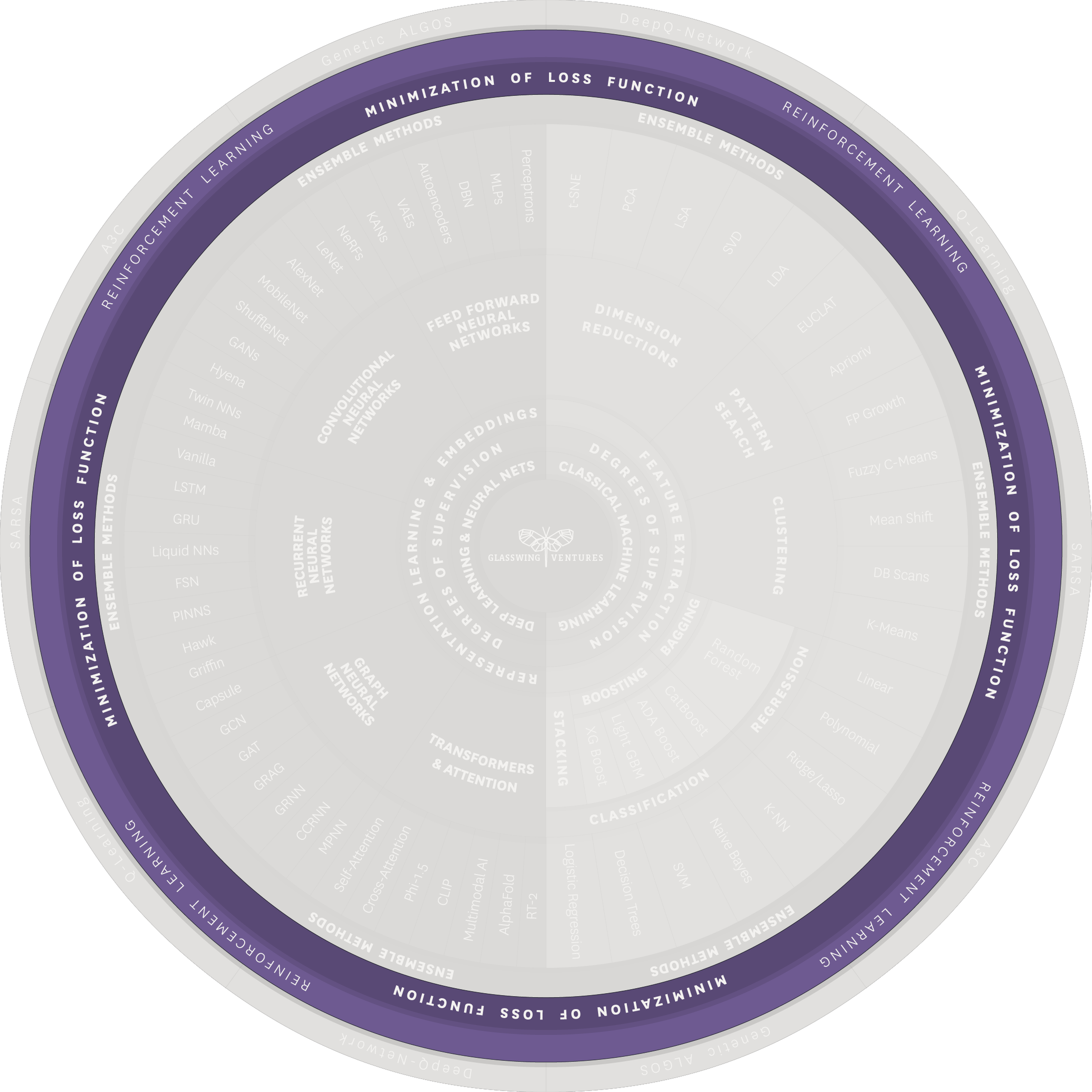
The most common methods of training ML models are Minimization of Loss Function and Reinforcement Learning.
Minimization of Loss Function involves adjusting the parameters and weights of the model to minimize the discrepancy between its predicted outputs and the actual outputs. The process of making adjustments, evaluating the model’s predicted outputs, and making further adjustments is repeated iteratively until the discrepancy is sufficiently small.
Reinforcement Learning (RL), used for self-driving cars, involves the use of rewards (positive reinforcement) and penalties (negative reinforcement) to incentivize the model to adjust its outputs. Value-based RL—often executed with algorithms such as Q-learning and SARSA, which are included in the outermost layer of the Palette—is a common approach by which the model learns to associate certain actions with rewards and adapt to different situations. This approach is useful in scenarios where it is impractical to provide detailed supervision for every individual step or state change.
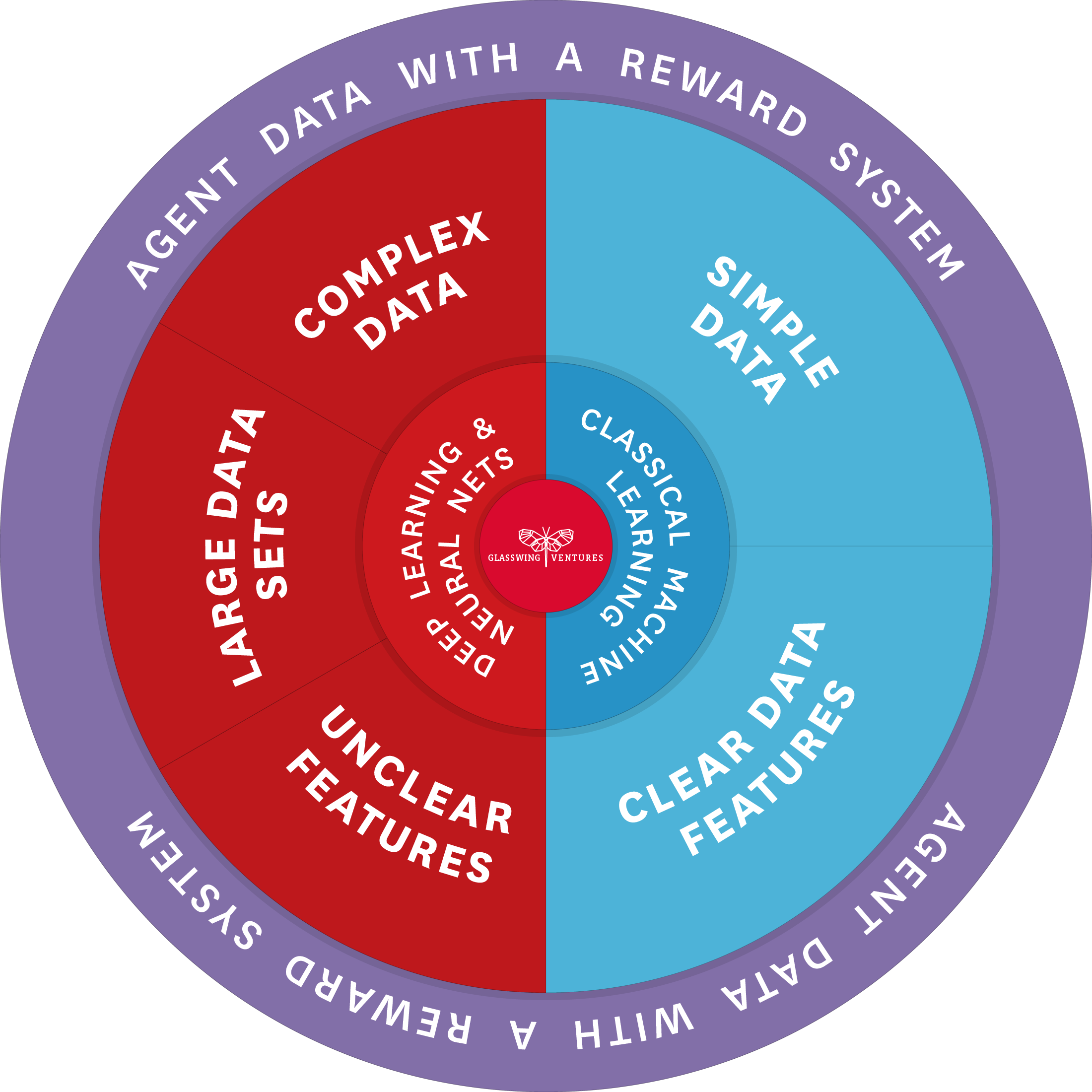
AI—and for that matter, the value and usefulness of Classical ML and Deep Learning—relies on the use of data for training and performance. As shown in this view of the Glasswing AI Palette, the type of data with which one trains her or his model depends on whether one is working with Classical ML or Deep Learning. To leverage the former, one needs to select a simple data set and design features, varying in difficulty depending on the data set. In contrast, Deep Learning has the capability to learn these representations autonomously. Given Deep Learning is particularly suited for complex tasks, the volume of data needed in Deep Learning is typically larger than in Classical ML due to the larger number of model parameters. In either case, the data corresponds to the architectures and techniques that are best suited to it.
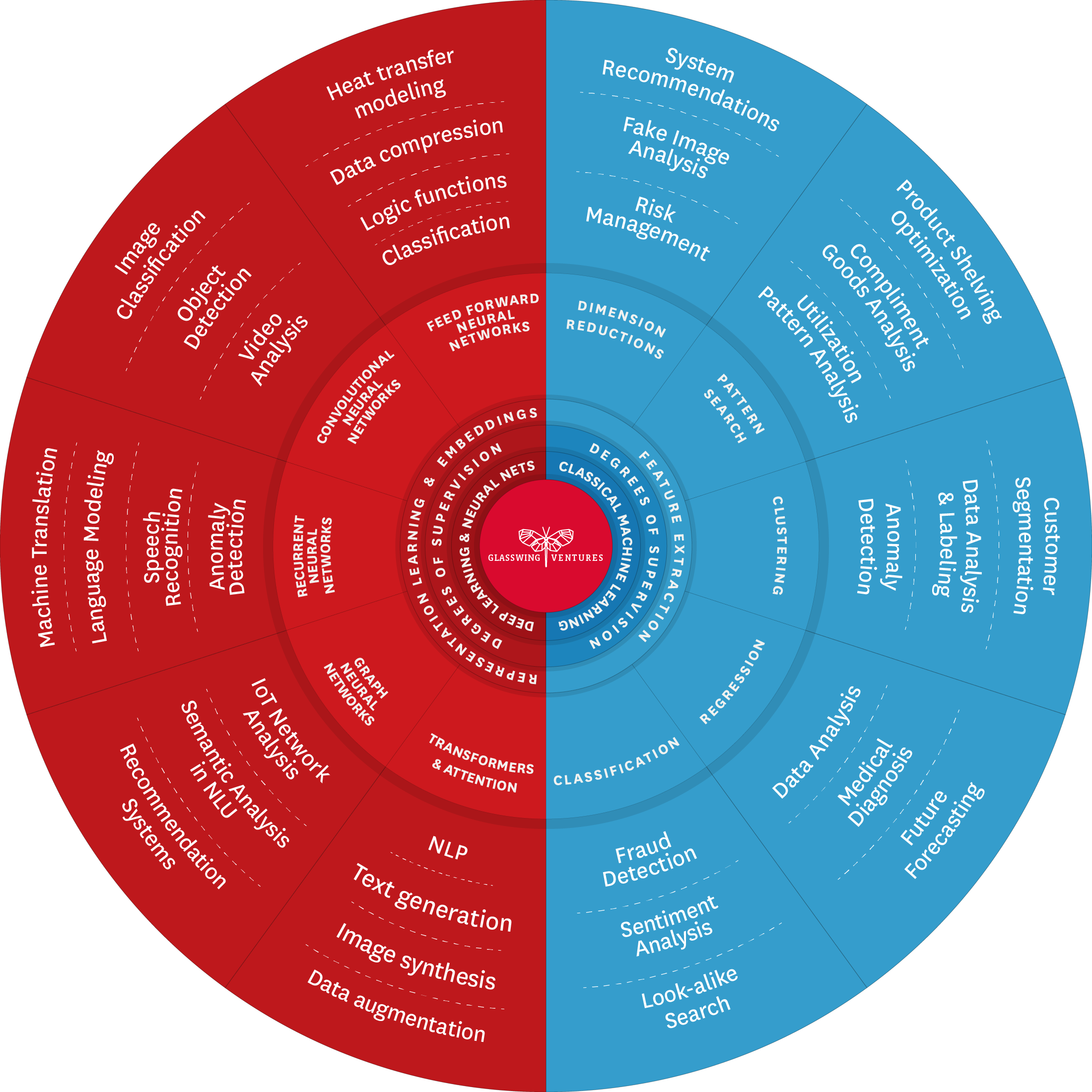
In this view of the Glasswing AI Palette, the outermost ring matches use cases with the architectures and techniques best suited to address them. The emphasis on first developing a clear, well-defined use case grounded in domain expertise is a crucial step often overlooked in the rush to leverage new algorithms. By deeply understanding the specific domain—its challenges, nuances, and needs—developers can create AI systems that are truly relevant, differentiated, and valuable. This approach increases the likelihood of the technology’s adoption and success and mitigates the risk of creating solutions that are technically advanced, yet practically redundant or inefficient. It is about aligning technological innovation with the genuine needs of a specific field, making the technology a means to an end, not an end in itself.
This is the power of the Glasswing AI Palette: If a startup founder or enterprise executive knows the use case she wants to solve for, but does not know how to apply AI to it, the AI Palette points her in the right direction to get started. For example, on the Classical ML side of the Palette, one can see that clustering is the best technique for use cases that require customer segmentation. On the Deep Learning side, one can see that Convolutional Neural Networks (CNNs) are the best architectures for image classification use cases.
To create a valuable AI solution, one must carefully consider the use case she or he is solving for and, from there, select the appropriate architecture, technique(s), training methodology, etc. Our expertise in these facets enables us to identify differentiated solutions, positioning Glasswing as the premier early-stage investor for frontier technology companies that are reshaping the enterprise and cybersecurity markets.
As the field of AI evolves, so too will the Glasswing AI Palette. Because it is designed to help founders, executives, and investors get started with AI, the Glasswing AI Palette is not meant to be all-encompassing—it is meant to cover the biggest categories and concepts in the field.
We have open-sourced this framework for the benefit of the business and venture capital communities, and we want your input to help us improve it. If you have ideas, please send us an email at info@glasswing.vc with the subject line Glasswing AI Palette.